



Online Gaming Leader Board
Online games show a leader board showcasing the top 10/100 players on their platform. Most of these games are online and the leader board keeps getting updated in real time. Assume that a maximum of a million users will be logged into your gaming platform at any given time. The game may take 5 minutes or even an hour to complete. When the game is over, the score of that individual will be added to the leader board and only the top 100 players will be shown to the gamers. The leader board is an always on widget even while the user is playing a game on your system. This leader board has 3 sections, (a) all time high score, (b) last week high score and (c) last hour high score. All time high score is just a static list and the score of each user gets updated as soon as they complete the game. But the (b) and (c) are a dynamic list created from a moving time window of the last 1 week and last 1 hour.
How would you design your system while addressing the below main requirements.
- Latency of leader board response should be under 100 milliseconds.
- Leader board API could be called with as high as 100K requests per minute frequency
- Leader board API response should be consistent across all the gamers
- When any game completes, the leader board should get updated within the next second across all the gamers
- Redundancy and fault tolerance. If my application server or database or network infrastructure crashes, the leader board should continue to run.
- Need to bring back the service back online in fastest possible time in case of a crash The design should include the choice of technology (language if you may, database choices etc..) you will use to create this setup based on your past experience. It should also include thoughts on how it will be deployed on a cloud infrastructure to cater to automatic scaling requirements. For the above performance, concurrency and redundancy requirements specify how will you plan for the capacity of your infrastructure.
Solution
In summary of the solution, will be implementing a solution based on -
- Persistent storage to store score based on events (in our case ending of a game)
- Cache with a data structure to implement the effective retrieval of top K players
- Application logic exposed in form of rest based microservices -
- UPDATE SCORE based on Player Id and Points
- LEADER BOARD based on the time range (ALL/WEEK/HOUR)
Data Modelling
As in our problem we are more focusing on the idea of solving, leader board problem, I am focusing on that part of data modelling right now.
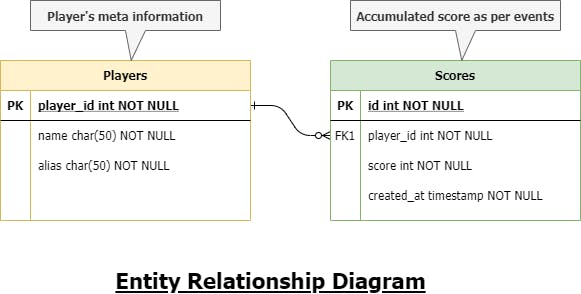
I have chosen MySQL as my preferred choice of database here cause it’s consistent with high throughput on aggregation with properly indexed fields.
Other honourable mentions could be -
- MongoDB (with imperative query language and power of map-reduce that’s highly efficient for aggregations)
- OpenTSDB (time-series database, still exploring more about the use case and practical usage especially for monitoring part along with Grafana)
Below is the E-R diagram for the score table -
Capacity Estimation
Database
Taking into consideration our Scores table, the max size per entry will be somewhere around -
Integer fields = 4 x 3 = 12 bytes Timestamp = 4 bytes Total = 16 bytes MAX per entry
Approximately for 1 Million users, we have active games suppose 1000 per user, comes out to be 1 Billion as an estimate for records
16 x 1 Billion = 16 GB (table size)
We can have either master-slave configuration of MySQL replicas for failsafe or we can keep all master configuration in circular replication providing better fault tolerance. Cache
For REDIS the memory footprints are pretty standard To give you a few examples (all obtained using 64-bit instances):
An empty instance uses ~ 3MB of memory. 1 Million small Keys -> String Value pairs use ~ 85MB of memory. 1 Million Keys -> Hash value, representing an object with 5 fields, use ~ 160 MB of memory.
Considering we have 3 buckets - ALL/WEEK/HOUR = 160 x 3 = 480 or max 512 MB RAM
In terms of distributed cache replicas, we can keep 2-3 of them.
Application
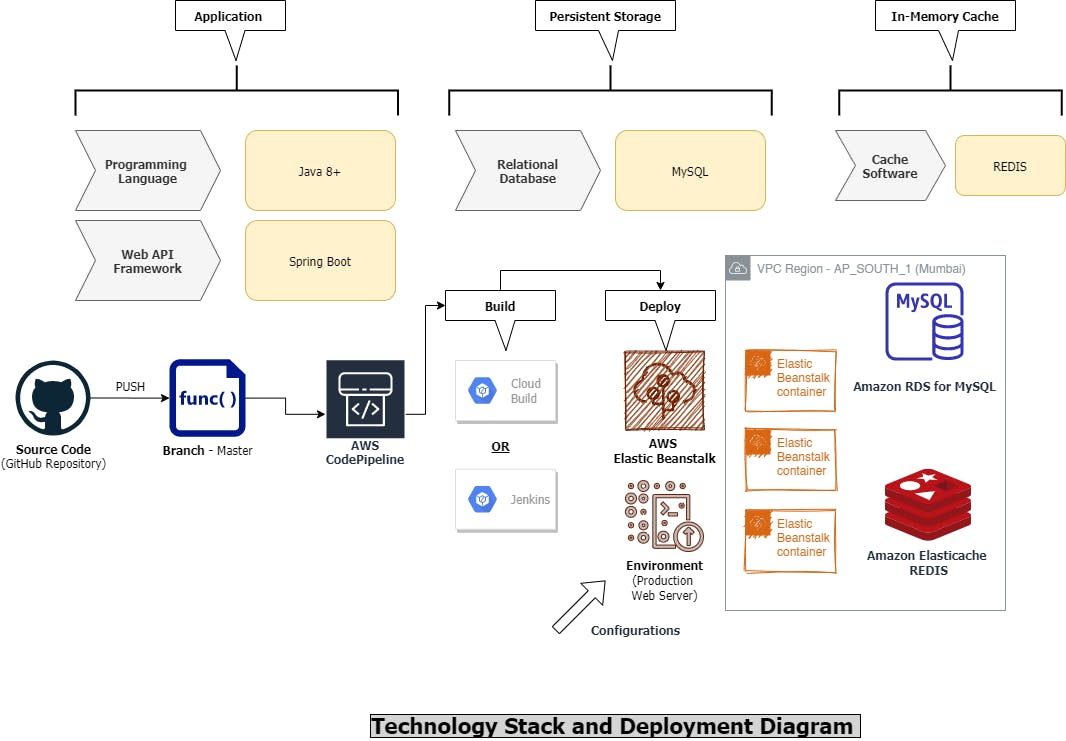
On the application side it’s pretty straightforward in terms of application clusters, to start we can have auto-scaling instances configured in AWS elastic beanstalk, for the start we can boot our application from 4 servers instances running on docker containers.
Java Spring Boot Application -> Image (registered to docker hub or another private repository)-> Container (used by EBS along with credentials/configurations)
Load balancer - AWS ELB (Elastic Load Balancer) works fine in case of request load distribution as well, or we can alternatively use a slightly more cost-effective tool - NGINX
Optional (but good to have) - Varnish the best tool for request collapsing to overcome the “stampede effect” on our leader board API for performance improvements.
System Architecture
Following is the design proposed for the solution majorly built on AWS Cloud.

Technology and Deployment Flow
Considering our version control of source code to be git and using cloud repository provider GitHub, PFB my proposed solution for the same -
Solution Implementation
In terms implementation module there are two main parts of it -
Part 1: Updates
Section A. INITIAL DATA SET CREATION This will be a two-step process in 3 different categories of the leader board -
Step 1: Retrieval of data from the persistence storage i.e. MySQL like
QUERY -
SELECT player_id, SUM(score) as score_total FROM Scores GROUP BY player_id ORDER BY score_total DESC (additionally the query will have limits on a date in case of WEEK and HOUR)
NOTE: INDEX - Must have on player_id, possibly can be added to created_at
Step 2: Addition to Sorted Set in Redis, explanations -
HOW DATA WILL BE STORED?
- Data will be stored in the format of - Key (
PLAYER_ID) and value (SUM OF SCORE TIME BOUND) - Using ZADD command taking 3 arguments it will be added to the relevant set (ALL/WEEK/HOUR) Ex: (“
name_of_set”,key,value) - Only WEEK and HOUR based sets have TTL a calendar week and a clock hour respectively, so practically HOUR based set will be created 24 times a day and WEEK based set 52 times a year.
- Data will be stored in the format of - Key (
WHY?
- Most of the operations supported by the Sorted Set take logarithmic time
O(log(n)), which means that its execution time even for huge data sets is going to be very low. - And in the case of just accessing the score of a single player complexity will be
O(1).
- Most of the operations supported by the Sorted Set take logarithmic time
Section B. REGULAR UPDATE
- For the case of WEEK and HOUR, the new entries coming to score tables will be added to SET for writing directly with modifications as a summation to existing score in sets
- For ALL time we can move such updates to Async mode to avoid latency.
Part 2: Reads
One our creation and modification of Sorted sets in REDIS is done, we can move towards the leader board retrieval part, so we can leverage the power of ZREVRANGE command like --
ZREVRANGE name_of_set 0 99 WITH SCORES
This will directly fetch top 100 players with a complexity of -
O(log (N) + M) // where N is total elements, M is top few elements required
In our case M is negligible as compared to N practicality otherwise the time will be close to linear.
Summary
In the end, what we have here is the design and estimated implementation, problems and challenges will be the part of final implementation both in terms of code development and solutions architecting (mostly configurations of cloud infrastructure)
PS: The ideas and solutions implemented above can be considered as the first draft and are subjected to further improvements as upcoming iterations.